All About Data
Contents
All About Data#
This lecture attempts to give a broad overview of Earth and Environment Science data formats, exchange protocols, and best practices.
What is (are) data?#
Ultimately, as we know, all digital data are just 1s and 0s. Each 1 or 0 value is called a bit. Bits are usually grouped together in groups of 8 bits, called a byte. A byte can represent \(2^8\), or 256, distinct values. We can choose to encode and organize the bytes in many different ways to represent different types of information.
Data Encoding#
Encoding is the way that we map raw bytes to meaningful values.
Numerical Data#
The most straightforward way to interpret a byte is as an integer.
value = 0b10101010 # 1 byte base-2 literal
value
170
However, many different numerial data types can be encoded as bytes. The more bytes we use for each value, the more range or precision we get.
import numpy as np
print(np.dtype('i2'), np.dtype('i2').itemsize, "bytes")
print(np.dtype('f8'), np.dtype('f8').itemsize, "bytes")
print(np.dtype('complex256'), np.dtype('complex256').itemsize, "bytes")
int16 2 bytes
float64 8 bytes
complex256 32 bytes
Text Data#
We can also encode text as bytes.
The simplest encoding is ASCII (American Standard Code for Information Interchange). ASCII uses one byte per character and therefore the ASCII alphabet only contains 256 different characters.

As computers became more powerful, and the computing community grew beyond the US and Western Europe, a more inclusive character encoding standard called Unicode took hold. The most common encoding is UTF-8. UTF-8 uses four bytes per character. This web page the the Jupyter Notebook it was generated from all use UTF-8 encoding.
Fun fact: emojis are UTF-8 characters.
"😀".encode()
b'\xf0\x9f\x98\x80'
Single values will only take us so far. To represent scientific data, we need to think about data organization.
Tabular Data#
A very common type of data is “tabular data”. We discussed it already in our Pandas lecture. Tabular data consists of rows and columns. The columns usually have a name and a specific data type. Each row is a distinct sample.
Here is an example of tabular data
Name |
Mass |
Diameter |
|---|---|---|
Mercury |
0.330 \(\times 10^{24}\) kg |
4879 km |
Venus |
4.87 \(\times 10^{24}\) kg |
12,104 km |
Earth |
5.97 \(\times 10^{24}\) kg |
12,756 km |
(Via https://nssdc.gsfc.nasa.gov/planetary/factsheet/)
The simplest and most common way to encode tabular data is in a text file as CSV (comma-separated values). CSV is readable by humans and computer programs.
For larger datasets, Apache Parquet is a good alternative. Parquet files are not human readable, but they can be parsed by computers much more quickly and efficiently. They also use compression to achieve a smaller file size compared to CSV.
Multiple related tabular datasets can be stored and queried in a relational database. Databases are very useful but beyond the scope of this class.
Array Data#
When we have numerical data that are organized into an N-dimensional rectangular grid of values, we are dealing with array data.
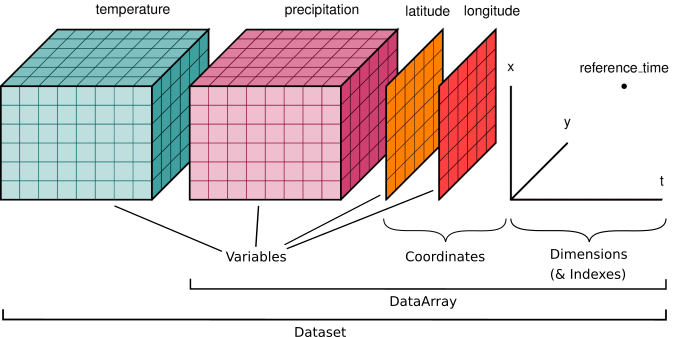
(via http://xarray.pydata.org/en/stable/user-guide/data-structures.html)
In python, we work with Array data in Numpy and Xarray.
Array data can be stored in the following standard formats:
Hierarchical Data Format (HDF5) - Container for many arrays
Network Common Data Form (NetCDF) - Container for many arrays which conform to the NetCDF data model
Zarr - New cloud-optimized format for array storage
TileDB Embedded - New cloud-optimized format for array storage
“GIS” Data#
A common term in Earth and Environmental Data Analysis is “GIS”: Geographical Information Systems The term GIS was coined by the company ESRI and is most commonly associated with that company’s software products like ArcGIS. Are we doing “GIS” in this class? Hard to say for sure. However, it is important to understand some of the common terminology from GIS as it relates to data.
Raster Data#
From ESRI’s definition:
In its simplest form, a raster consists of a matrix of cells (or pixels) organized into rows and columns (or a grid) where each cell contains a value representing information, such as temperature. Rasters are digital aerial photographs, imagery from satellites, digital pictures, or even scanned maps.

(Image credit Environmental Systems Research Institute, Inc.)
Raster data is thus similar to array data, but specialized to 2D images of the earth. Raster data nearly always includes a Coordinate Reference System that allows one to translate the pixels of the image to specific geographic locations on Earth.
The most common format for Raster data is the GeoTIFF and its recent evolution, the Cloud-optimized GeoTIFF (CoG). In Python, raster data is commonly read with rasterio. Rasterio integrates with Xarray via the rioxarray package, allowing you to read geotiffs directly into Xarray.
Vector Data#
From the Data Carpentry vector data lesson:
Vector data structures represent specific features on the Earth’s surface, and assign attributes to those features. Vectors are composed of discrete geometric locations (x, y values) known as vertices that define the shape of the spatial object. The organization of the vertices determines the type of vector that we are working with: point, line or polygon.
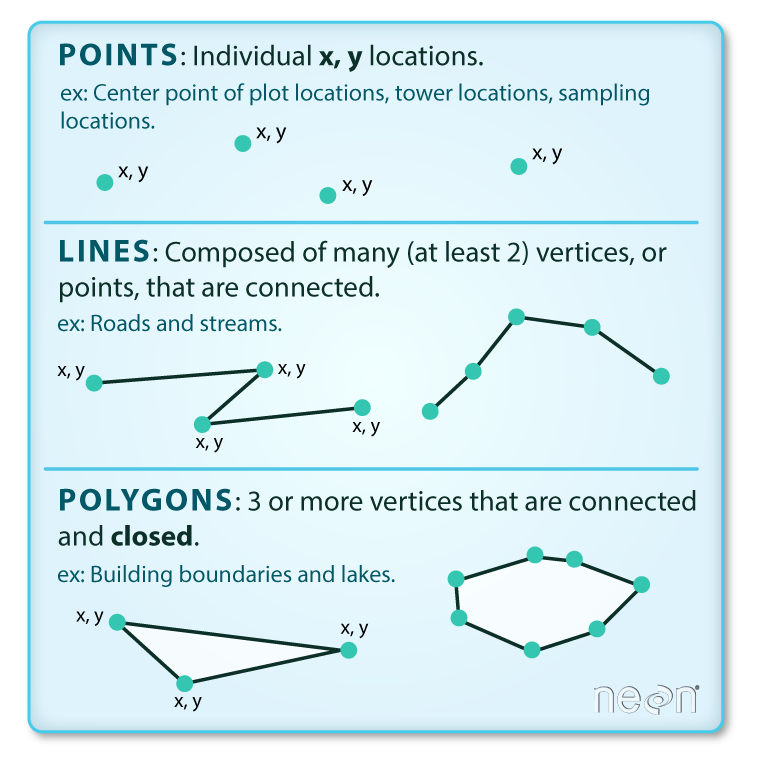
(Image credit: National Ecological Observatory Network (NEON))
There are many different file formats for vector data. One of the most common is the ESRI shapefile. However, others have argued that shapefile is not a good format and have promoted the use of other formats including:
Vector data can be read in python using Fiona and GeoPandas.
Graph Data#
Some phenomena are best represented as a discrete graph, consisting of nodes and edges (vertices).
Graph data can be stored in a range of different formats. In python, we can analyze graph data using NetworkX.
We do not work with graph data in this class, but it’s important to know it exists.
Unstructured Data#
Data that does not fit one of the above paradigms is often called “unstructured” data. Unstructured data is often characterized by nested or hierarchical structures.
A common container for unstructured data is JavaScript Object Notation (JSON). JSON can be read into a Python dictionary using the json package from the Python standard library.
Metadata#
Metadata are “data about the data”, for example:
Who created the dataset?
What is the license for the data?
What is the appropriate scholarly reference for the data?
What variables or fields are contained in the data?
What geographical or temporal extent does the data cover?
Metadata should attempt to follow established conventions and encoding formats to permit search engines or other tools to automatically “crawl” data repositories in order to index and catalog the data contained therein.
In Earth and Environmental science, we are fortunate to have widespread robust practices around metdata. For self-contained file formats like NetCDF, metadata can be embedded directly into the data files. Common metadata conventions for NetCDF-style data include:
Climate and Forecast (CF) Conventions - Commonly used with NetCDF data
Other types of data may have other metadata conventions. Schema.org provides a very general framework for metadata.
How do programs access data?#
Reproducibility and Manual Download Steps#
To perform a reproducible scientific workflow, you cannot assume that the input data for your analysis are already present on the computer where the code is running. Such code may work for you, but it won’t work when you share it with others, unless they happen to have the exact same files in the same locations.
Instead, your code should aim to explicitly acquire the data from the original data provider via a persistent identifier such as a DOI or stable URL. Manual data download steps, in which the user must click on buttons on a website, save the files manually, and then move them to a specific location, are a significant barrier to reproducibility and open science.
Below we will explore some strategies for writing data analysis code that avoids manual download steps.
Loading Data Directly Over the Network#
A great way of loading data is to read it directly over the network into your program. When you write code in this way, you avoid any reliance on the local filesystem and local path names. This is particularly effective for smallish datasets (< 100 MB) that are quick to transfer.
HTTP streams#
HTTP - HyperText Transfer Protocol - is the standard way that web pages and other data are transferred over the internet. HTTP connections are typically established via URLs - Universal Resource Locators. The URL for this book is
https://earth-env-data-science.github.io
When you point your web browser to this URL, it downloads the data (in this case, unicode text files structured as HTML) to your computer for viewing. A key point is that URLs are the same from every computer.
Data analysis applications can also get data over HTTP. For example, Pandas can directly open files from http[s]:// URLs.
If you can find such a link to your dataset, you can pass it directly to Pandas.
However, sometimes it takes some sleuthing to find the right link.
As an example, let’s consider the NASA Meteorite Landings Database.
When we go to this site we see something like this:
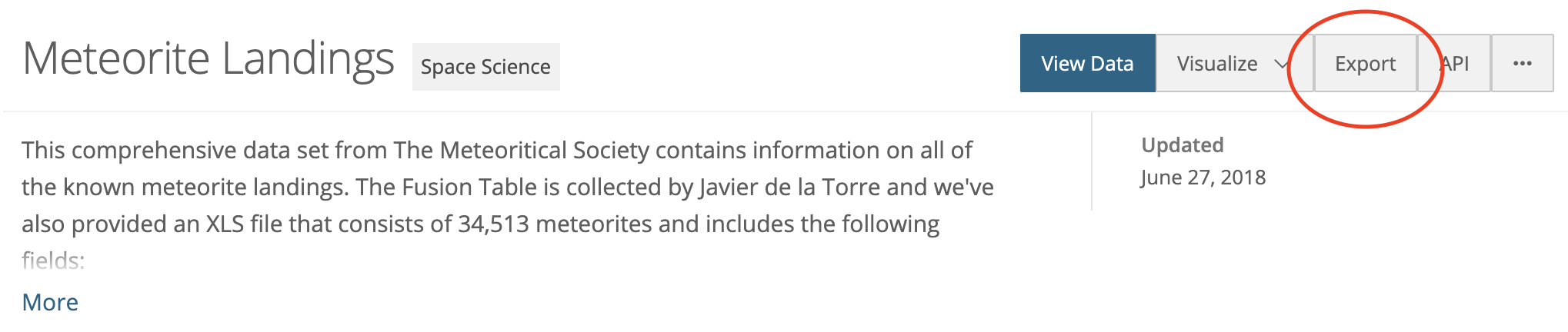
Clicking the “export” button gives us an option to export CSV, which we know pandas can read. If we just click the “CSV” button, we download the file to our computer (not what we want). Instead, right click or CTRL-click the download link and select “Copy Link Address”.

Pasting the results into our code editor gives us the desired URL.
https://data.nasa.gov/api/views/gh4g-9sfh/rows.csv?accessType=DOWNLOAD"
We can feed this directly to Pandas.
import pandas as pd
url = "https://data.nasa.gov/api/views/gh4g-9sfh/rows.csv?accessType=DOWNLOAD"
df = pd.read_csv(url)
df.head()
| name | id | nametype | recclass | mass (g) | fall | year | reclat | reclong | GeoLocation | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Aachen | 1 | Valid | L5 | 21.0 | Fell | 01/01/1880 12:00:00 AM | 50.77500 | 6.08333 | (50.775, 6.08333) |
| 1 | Aarhus | 2 | Valid | H6 | 720.0 | Fell | 01/01/1951 12:00:00 AM | 56.18333 | 10.23333 | (56.18333, 10.23333) |
| 2 | Abee | 6 | Valid | EH4 | 107000.0 | Fell | 01/01/1952 12:00:00 AM | 54.21667 | -113.00000 | (54.21667, -113.0) |
| 3 | Acapulco | 10 | Valid | Acapulcoite | 1914.0 | Fell | 01/01/1976 12:00:00 AM | 16.88333 | -99.90000 | (16.88333, -99.9) |
| 4 | Achiras | 370 | Valid | L6 | 780.0 | Fell | 01/01/1902 12:00:00 AM | -33.16667 | -64.95000 | (-33.16667, -64.95) |
This code will work from any computer on the internet! 🎉
OPeNDAP#
OPeNDAP - “Open-source Project for a Network Data Access Protocol” - is a highly established protocol for tranferring NetCDF-style data over HTTP. NetCDF and Xarray can open OPeNDAP links directly.
As an example, we will use a dataset from the IRI Data Library:
Clicking on the “Data Files” tab shows a link to “OPeNDAP”, which point to the URL http://iridl.ldeo.columbia.edu/expert/SOURCES/.NOAA/.NCEP/.CPC/.UNIFIED_PRCP/.GAUGE_BASED/.GLOBAL/.v1p0/.Monthly/.RETRO/.rain/dods. We can open this directly in Xarray.
import xarray as xr
url = "http://iridl.ldeo.columbia.edu/expert/SOURCES/.NOAA/.NCEP/.CPC/.UNIFIED_PRCP/.GAUGE_BASED/.GLOBAL/.v1p0/.Monthly/.RETRO/.rain/dods"
# decode_times=False is required because the IRI Data Library uses non-standard encoding of times
ds = xr.open_dataset(url, decode_times=False)
ds
<xarray.Dataset>
Dimensions: (X: 720, T: 324, Y: 360)
Coordinates:
* X (X) float32 0.25 0.75 1.25 1.75 2.25 ... 358.2 358.8 359.2 359.8
* T (T) float32 228.5 229.5 230.5 231.5 ... 548.5 549.5 550.5 551.5
* Y (Y) float32 -89.75 -89.25 -88.75 -88.25 ... 88.25 88.75 89.25 89.75
Data variables:
rain (T, Y, X) float32 ...
Attributes:
Conventions: IRIDL- X: 720
- T: 324
- Y: 360
- X(X)float320.25 0.75 1.25 ... 359.2 359.8
- standard_name :
- longitude
- pointwidth :
- 0.5
- gridtype :
- 1
- units :
- degree_east
array([2.5000e-01, 7.5000e-01, 1.2500e+00, ..., 3.5875e+02, 3.5925e+02, 3.5975e+02], dtype=float32) - T(T)float32228.5 229.5 230.5 ... 550.5 551.5
- pointwidth :
- 1.0
- calendar :
- 360
- gridtype :
- 0
- units :
- months since 1960-01-01
array([228.5, 229.5, 230.5, ..., 549.5, 550.5, 551.5], dtype=float32)
- Y(Y)float32-89.75 -89.25 ... 89.25 89.75
- standard_name :
- latitude
- pointwidth :
- 0.5
- gridtype :
- 0
- units :
- degree_north
array([-89.75, -89.25, -88.75, ..., 88.75, 89.25, 89.75], dtype=float32)
- rain(T, Y, X)float32...
- pointwidth :
- 0
- standard_name :
- lwe_precipitation_rate
- file_missing_value :
- -999.0
- history :
- Boxes with less than 0.0% dropped
- units :
- mm/day
- long_name :
- Monthly Precipitation
[83980800 values with dtype=float32]
- Conventions :
- IRIDL
Filesystem-Spec (fsspec)#
Filesystem Spec (fsspec) is a project to provide a unified pythonic interface to local, remote and embedded file systems and bytes storage.
Fsspec allows us to access many different types of remote files in a simple, uniform way. Fsspec has many built in implementations including local files, HTTP, FTP, and Zipfile. Additional packages implement the fsspec interface to provide access to cloud storage. These include
s3fs for Amazon S3 and other compatible stores
gcsfs for Google Cloud Storage
adlfs for Azure DataLake storage
and several others.
Cloud Object Storage#
Cloud object storage is the easiest and most performant way to share data over the internet. Data stored in cloud object storage is always available and can be read extremely quickly, particularly from the same cloud region.
More TODO here…
Local Files#
Some programs require data to be on your local hard drive to read.
To download files to your local computer, we strongly recommend Pooch.
Here is an example of using Pooch to download data from the CRESIS Radar Database. As with the examples above, the first step is to nagivate to web page and try to figure out the actual URL of the files you want to download.
import pooch
POOCH = pooch.create(
path=pooch.os_cache("2017_Antarctica_P3/CSARP_mvdr"),
base_url="https://data.cresis.ku.edu/data/rds/2017_Antarctica_P3/CSARP_mvdr/20171124_03/",
registry={
"Data_img_02_20171124_03_020.mat": None,
}
)
local_fname = POOCH.fetch("Data_img_02_20171124_03_020.mat")
local_fname
'/home/jovyan/.cache/2017_Antarctica_P3/CSARP_mvdr/Data_img_02_20171124_03_020.mat'
The file is now saved locally and can be read, e.g. with h5py.
import h5py
f = h5py.File(local_fname)
list(f)
['#refs#',
'Bottom',
'Data',
'Elevation',
'GPS_time',
'Heading',
'Latitude',
'Longitude',
'Pitch',
'Roll',
'Surface',
'Time',
'param_combine',
'param_csarp',
'param_records']
Here is another example
POOCH = pooch.create(
path=pooch.os_cache("greenland_ice_sheet"),
base_url="https://zenodo.org/record/4977910/files/",
registry={
"vel_2010-07-01_2011-06-31.nc": "md5:80ad1a3c381af185069bc032a6459745",
}
)
fname = POOCH.fetch("vel_2010-07-01_2011-06-31.nc")
fname
'/home/jovyan/.cache/greenland_ice_sheet/vel_2010-07-01_2011-06-31.nc'
This downloads a netCDF file we can read with Xarray:
ds = xr.open_dataset(fname)
ds
<xarray.Dataset>
Dimensions: (x: 10018, y: 17946)
Coordinates:
* x (x) float64 -6.38e+05 -6.378e+05 ... 8.644e+05 8.646e+05
* y (y) float64 -6.576e+05 -6.578e+05 ... -3.349e+06 -3.349e+06
Data variables:
coord_system |S1 b''
VX (y, x) float32 ...
VY (y, x) float32 ...
Attributes: (12/27)
Conventions: CF-1.6
Metadata_Conventions: CF-1.6, Unidata Dataset Discovery v1.0, GDS v2.0
standard_name_vocabulary: CF Standard Name Table (v22, 12 February 2013)
id: vel_final.t.nc
title: MEaSURES Antarctica Ice Velocity Map 450m spacing
product_version:
... ...
time_coverage_start: 1995-01-01
time_coverage_end: 2016-12-31
project: NASA/MEaSUREs_UC-Irvine
creator_name: J. Mouginot
comment:
license: No restrictions on access or use- x: 10018
- y: 17946
- x(x)float64-6.38e+05 -6.378e+05 ... 8.646e+05
- long_name :
- Cartesian x-coordinate
- standard_name :
- projection_x_coordinate
- axis :
- X
- units :
- m
array([-638000., -637850., -637700., ..., 864250., 864400., 864550.])
- y(y)float64-6.576e+05 ... -3.349e+06
- long_name :
- Cartesian y-coordinate
- standard_name :
- projection_y_coordinate
- axis :
- Y
- units :
- m
array([ -657600., -657750., -657900., ..., -3349050., -3349200., -3349350.])
- coord_system()|S1...
- ellipsoid :
- WGS84
- false_easting :
- 0.0
- false_northing :
- 0.0
- grid_mapping_name :
- polar_stereographic
- longitude_of_projection_origin :
- 45.0
- latitude_of_projection_origin :
- 90.0
- standard_parallel :
- 70.0
- straight_vertical_longitude_from_pole :
- 0.0
array(b'', dtype='|S1')
- VX(y, x)float32...
- long_name :
- Ice velocity in x direction
- standard_name :
- land_ice_x_velocity
- units :
- meter/year
- coordinates :
- lon lat
- grid_mapping :
- coord_system
[179783028 values with dtype=float32]
- VY(y, x)float32...
- long_name :
- Ice velocity in y direction
- standard_name :
- land_ice_y_velocity
- units :
- meter/year
- coordinates :
- lon lat
- grid_mapping :
- coord_system
[179783028 values with dtype=float32]
- Conventions :
- CF-1.6
- Metadata_Conventions :
- CF-1.6, Unidata Dataset Discovery v1.0, GDS v2.0
- standard_name_vocabulary :
- CF Standard Name Table (v22, 12 February 2013)
- id :
- vel_final.t.nc
- title :
- MEaSURES Antarctica Ice Velocity Map 450m spacing
- product_version :
- summary :
- keywords :
- keywords_vocabulary :
- platform :
- sensor :
- date_created :
- 2017-06-14T23:00:25.00003874301591Z
- institution :
- Department of Earth System Science, University of California, Irvine
- cdm_data_type :
- Grid
- geospatial_lat_units :
- degrees_north
- geospatial_lon_units :
- degrees_east
- geospatial_lat_min :
- 60
- geospatial_lat_max :
- 90
- geospatial_lon_min :
- -180
- geospatial_lon_max :
- 180
- spatial_resolution :
- 150 m
- time_coverage_start :
- 1995-01-01
- time_coverage_end :
- 2016-12-31
- project :
- NASA/MEaSUREs_UC-Irvine
- creator_name :
- J. Mouginot
- comment :
- license :
- No restrictions on access or use
Best practices for data sharing: FAIR#
The acronym FAIR - Findable, Accessible, Interoperable, Reusable - has recently caught on as the gold standard for data sharing. The FAIR principles are growing rapidly in the geoscience community.
Here we repeat and discuss the FAIR principles (via https://www.force11.org/group/fairgroup/fairprinciples)
To be Findable:#
F1. (meta)data are assigned a globally unique and eternally persistent identifier.
F2. data are described with rich metadata.
F3. (meta)data are registered or indexed in a searchable resource.
F4. metadata specify the data identifier.
To be Accessible:#
A1 (meta)data are retrievable by their identifier using a standardized communications protocol.
A1.1 the protocol is open, free, and universally implementable.
A1.2 the protocol allows for an authentication and authorization procedure, where necessary.
A2 metadata are accessible, even when the data are no longer available.
To be Interoperable:#
I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
I2. (meta)data use vocabularies that follow FAIR principles.
I3. (meta)data include qualified references to other (meta)data.
To be Re-useable:#
R1. meta(data) have a plurality of accurate and relevant attributes.
R1.1. (meta)data are released with a clear and accessible data usage license.
R1.2. (meta)data are associated with their provenance.
R1.3. (meta)data meet domain-relevant community standards.
Persistent Identifiers (PI / PID)#
Persistent identifier are quasi-permanent unique identifiers that can be used to look up data, articles, books, etc. They are a key aspect of making data Findable. Digitial persistent identifiers are usually HTTP URLs that are guaranteed to continue working for a long time (in contrast to general URLs, which could change or disappear at any time.)
Digital Object Identifiers#
In science, the DOI system has become a univerally accepted way to identify and find digital scholarly objects.
A DOI consists of a string of characters. Prepending the URL https://doi.org/ to a DOI will generate a web link that can be used to look up the object.
Publishers (of journal articles, books, data repositories, etc.) will typical generate (or “mint”) a DOI for new content when it is published. The publisher commits to making the DOI work “forever”. That’s why not just anyone can create a DOI; it’s a commitment.
Here are some examples of DOIs. Click the links to see where they go.
Product Type |
DOI |
DOI Resolver |
|---|---|---|
Article |
|
|
Dataset |
|
|
Software |
|
How can YOU can create FAIR data and code?#
What not to do#
Put the data / code on your personal website
Put the data / code in Google Drive / Dropbox / etc.
Put the data / code in GitHub
The problem with these solutions is that they are not persistent and therefore not findable.
Rough guide to FAIRly sharing data#
This guide applies to small data (< 10 GB). Sharing medium or large datasets is more difficult and complicated–clear solutions and best practices do not yet exist.
Step 1: Quality control the data and metadata#
Before sharing a dataset, you should apply quality control to ensure there are not bad or incorrect values.
Choose a standard data format appropriate to the structure of your data, as reviewed above.
You also need to generate metadata for your data.
If your format supports embedded metadata (e.g. NetCDF, Zarr), you should provide it following one or more of the metadata conventions reviewed above (e.g. CF, ACDD, etc.)
If not (e.g. csv files), you should provide a separate metadata file (e.g. README.txt) to accompany your data.
Once your data and metadata quality control is complete, export the data file[s] to a local folder.
Step 2: Upload the data to Zenodo#

Our recommended data repository is Zenodo.
Built and developed by researchers, to ensure that everyone can join in Open Science.
The OpenAIRE project, in the vanguard of the open access and open data movements in Europe was commissioned by the EC to support their nascent Open Data policy by providing a catch-all repository for EC funded research. CERN, an OpenAIRE partner and pioneer in open source, open access and open data, provided this capability and Zenodo was launched in May 2013.
In support of its research programme CERN has developed tools for Big Data management and extended Digital Library capabilities for Open Data. Through Zenodo these Big Science tools could be effectively shared with the long-tail of research.
First create a Zenodo account: https://zenodo.org/signup/ Make sure to link your Zenodo account to your GitHub and ORCID accounts.
Then go to https://zenodo.org/deposit to deposit a new record. Follow the instructions provided, and make sure to include as much metadata as you can. Make sure to choose an open-access license such as Creative Commons. This will make your data more Interoperable and Re-useable.
When all your data are uploaded and you have double-checked the metadata, you can click “Publish”. This will create a permanent archive for your data and generate a new DOI! 🎉
Step 3: Verify you can access the data#
Use the Pooch DOI downloader to download and open your data files from a Jupyter Notebook.
Here is an example:
doi = "doi:10.5281/zenodo.5739406"
fname = "wind_po_hrly.csv"
file_path = pooch.retrieve(
url=f"{doi}/{fname}",
known_hash="md5:cf059b73d6831282c5580776ac07309a",
)
file_path
'/home/jovyan/.cache/pooch/fc13d29563dcf659960ec752e43618fa-wind_po_hrly.csv'
pd.read_csv(file_path).head()
| date.time | ny_1_onshore | ny_2_onshore | newe_onshore | mw_onshore | newe_offshore | ny_offshore | rfce_offshore | srvc_offshore | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1/1/2011 0:00 | 0.725240 | 0.450004 | 0.693996 | 0.646463 | 0.759451 | 0.528019 | 0.353946 | 0.189323 |
| 1 | 1/1/2011 1:00 | 0.702001 | 0.446462 | 0.677913 | 0.688890 | 0.767231 | 0.530822 | 0.357297 | 0.212965 |
| 2 | 1/1/2011 2:00 | 0.670164 | 0.432219 | 0.645567 | 0.717634 | 0.764237 | 0.538845 | 0.374450 | 0.232722 |
| 3 | 1/1/2011 3:00 | 0.627149 | 0.436257 | 0.608017 | 0.745687 | 0.760258 | 0.541974 | 0.387670 | 0.246672 |
| 4 | 1/1/2011 4:00 | 0.580882 | 0.456108 | 0.584728 | 0.767698 | 0.759814 | 0.552363 | 0.393835 | 0.261140 |